I worked for a very large company from 2001 to 2003 as a mainframe operator and midrange administrator. The company datacenter consisted of multiple mainframes, roughly a thousand servers, a ridiculous amount of disk space, multiple tape silos, and 24/7 monitoring. Our job (98% of the time, anyways) was to drool on our keyboard in twelve hour shifts while we waited for some key system to blow up.
On January 25th, 2003 another system administrator from our Windows group contacted the data center regarding a worm that was spreading like wildfire through the Internet. This worm was named sapphire, although it came to be known as “slammer” because it completely saturated local networks while attempting to find other hosts to infiltrate, causing networks to become completely unresponsive. The worm propagated via a buffer overflow in Microsoft's “SQL Server” database software. This exploit had been well documented; a security briefing issued by Microsoft outlined the overflow in July of 2002 and shortly thereafter a patch was issued.
Checking our servers in the data center, I determined that our systems had not been patched (almost six months after the fact, I might add) and were completely vulnerable. However, our system had not been compromised because of a substantial firewall between the datacenter and general network traffic. I strongly advised my coworker to patch this vulnerability as soon as possible.
Fast forward six months: the entire datacenter network crashes spectacularly after slammer somehow found its way inside the internal network. All IP network traffic inside the datacenter was brought to a screeching halt as the worm completely saturated network resources. We could not login to Windows servers to shut them down; the only course of action at that point was to go through the entire datacenter and unplug every computer running SQL Server. Several “mission critical” systems were offline for hours, which cost a dollar figure I dare not mention. The source had been a lone developer who logged into the internal network via a VPN connection. It was truly an “OMG WTF!?” sort of moment, to use the parlance of our times. We all had to wipe the spittle off of our keyboards.
It is tempting to point a finger at Microsoft, but realistically that's not valid. The issue had been well documented a year prior so there is little to blame beyond our own inaction. Had our Windows administrators not been in a state of narcolepsy, this would have been a non-issue. Furthermore, the internal network had insufficient security; just because the traffic was internal did not mean it should be allowed to travel without scrutiny. Had internal company routers been setup to block extraneous network traffic on several key UDP ports, the entire issue would have been mitigated.
It is equally tempting to fault the people who wrote the worm. However, the truth is they exploited little more than complete incompentence.
Thursday, November 16, 2006
Monday, October 30, 2006
I am getting a degree in Computational Science
On my resume, I list that I have a degree in Computational Science, rather than the more frequently used term, Computer Science.
I do this for two reasons:
I do this for two reasons:
- "Computer Science" is a misnomer, in my opinion, and
- It helps me determine if people were paying attention when they read my resume. It's always a good talking point during an interview.
Why is Computer Science a misnomer? Well, for starters, "computer" is a noun. To expound upon this distinction further, the definition of a "computer" according to Microsoft is:
Any device capable of processing information to produce a desired result. No matter how large or small they are, computers typically perform their work in three well-defined steps: (1) accepting input, (2) processing the input according to predefined rules (programs), and (3) producing output.
...so, it's a "device" (noun) that is capable of processing information, or performing computations. According to Wikipedia, a computer is:
A computer is a machine for manipulating data according to a list of instructions known as a program.
...again, a computer is a "machine" (noun) for manipulating data, or performing computations. There are literally hundreds of definitions of "computer" available on the Internet, but the general theme is that it's an object that is capable of performing computation. In a general sense, what the general public considers to be a computer is the ugly beige box directly to their left. But in reality, it's much more general than that. An abacus is a computer in the sense that is capable of doing computation.
This is an important distinction; computational science really is not the study of computers themselves. Computer Science implies that it is the study of machines for manipulating data, but really it's the study of manipulating data. The late Edsger Dijkstra was quoted as saying:
Computer Science is no more about computers than astronomy is about telescopes.
...this coming from a guy who won the Turing Award means an awful lot. The implications of this otherwise comical quote are significant; astronomers don't study telescopes. They use telescopes to study celestial objects and phenomena. Computational Scientists don't study computers. They study computational topics that may or may not involve computers.
The way I see it, "Computer Science" is a term that should go away, because it is a misnomer. I think it should be replaced with three separate degrees that have some overlap, but focus on their respective titles:
- Computational Science - this is the study of--surprise, surprise--computation! As in, algorithms, data structures, programming languages, compilers, and the mathematical foundations of computation (e.g. graph theory, state theory, boolean algebra, number and type theory, etc.). It is almost more of a mathematical, logical and theoretical endeavor than an applied science, and is arguably more related to mathematics than any other field.
- Computer Engineering - this is the study of engineering computers, which can (and should) be generalized to the notion of creating devices to aid in computation. This is almost more of a degree in electrical engineering, but with a slant towards engineering devices that aid in computation.
- Software Engineering - the study of engineering software. At first this would appear redundant, but were that true, we could also say that Mechanical Engineering is redundant. Software Engineering is the applied arm of computational science; how do we apply theory and research in actual software? Sure, the theoretical approach to garbage collection is great and all, but how does that get applied in practical terms? Software Engineering can have overlap with Computer Engineering (e.g. firmware), but in general, Software is concerned with programmatic engineering verses hardware/electrical engineeering.
Obviously this could be subdivided more, but the idea is separating theoretical and/or mathematical endeavors from applied and/or vocational endeavors. This is not crazy, given that Mechanical Engineering is arguably an applied, vocational version of physics and mathematics. This is not to say it's a lesser degree or inferior, but the focus of a Mechanical Engineering is obviously quite different from Physics or Mathematics.
All of this bitching and moaning on my behalf often raises the question: why would anyone care about making such a nitpicky distinction? It matters because academia is a complete mess. I have attended three separate institutions, and all three of them seemed terribly confused about what "computer science" actually entailed. I believe part of this has to do with not taking the time to actually define what "computer science" may be, and why anyone would bother studying it.
To be continued...
Monday, October 23, 2006
Since IE7 is now released, this is a perfect time to explain why I'm stuck using both browsers, and the relative merits of both browsers, in my opinion.
I have always like FireFox better for several reasons. The biggest reason for me is something that nobody ever seems to mention: hit Ctrl-F in IE, and a Modeless dialog box pops up in front of the window. It looks a lot like this:
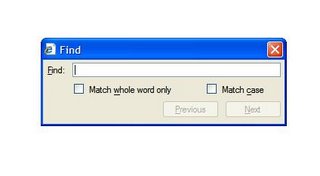

I have always like FireFox better for several reasons. The biggest reason for me is something that nobody ever seems to mention: hit Ctrl-F in IE, and a Modeless dialog box pops up in front of the window. It looks a lot like this:
A few things to note about this dialog:
- It is modeless and shows up on top of the very window you're trying to observe. This is annoying, because the information you're searching through is obscured by the dialog itself. Often times a search term ends up underneath the box itself, which is both irritating and annoying.
- The find feature itself is transactional, rather than real-time. That is, when you type in a word you're looking for, you then have to click on (or tab to) the "Find" button on the dialog. It does not start looking for the phrase the instant you type it.
- If the word does not exist on the page, yet another messagebox pops up, informing the user that no such word exists, prompting the user to click something to continue. Again, annoying.
FireFox's find box, on the other hand, looks like so:
...the two look surprisingly similar, however there's some huge differences:
- Firefox's find tool appears at the bottom of the browser window along the status bar. This means it never blocks what it is you're trying to look at. It is the logical place to have a find window, and very desireable to IE's modeless dialog box.
- As you type in the textbox, it dynamically searches for the string. In other words, as you typed in "Equal", it would highlight all instances of "e", then "eq", then "equ" and so forth. So the act of typing (rather than clicking some button off to the side) engages the search. This is decidedly preferable.
- Clicking on the "highlight all" button highlights all instances of the search term in an easy to spot yellow box.
- If the phrase is not found, it indicates it to you by putting the warning on the toolbar itself--not popping up another messagebox. This is highly desireable.
It's little things like that that make it for me. Sure, I have a billion options for searching for web pages, but once you get to the page you want, how do you find your information? Firefox's find mechanism is far more intuitive and user-friendly than IE's has ever been. Sadly MSFT has done nothing to fix this for IE7; it is the same crummy find mechanism included in the last several versions of Internet Explorer.
Another thing I love about Firefox is their "View Page Source" presents the source marked up and formatted. IE's uses notepad. It is possible to replace IE's with notepad++, which is vastly superior in almost all instances; however, the fact remains that out of the box, Firefox has much better HTML source viewer. It also has the DOM inspector and the error console, which are useful if you're developing web pages.
Sadly, I still use IE because it's the only thing that seems to be capable of correctly rendering MSDN, which I need to do my job.
Wednesday, October 11, 2006
The Economist and OSS
The Economist had an article on Open Source Software that I found interesting.
To summarize the article: the open-source model will continue to be applied in domains outside of software engineering and is a lucrative business model--albeit one with some outstanding issues. I agree with the former statement, but the latter is poorly reasoned and supported.
Example:
With regards to ensuring quality, the underlying assumption is that closed source, for-profit software development does have means of ensuring quality, which should set off a three-alarm fire in the collective brains of software developers everywhere. Closed source products that do not maintain quality are eliminated via natural selection (or some similar process), just as they are in the OSS model. It's pretty simple: release buggy commercial software, and users will start looking for other alternatives. Release buggy OSS, and users will start looking for other alternatives. Same concept applies.
I would add that capitalistic models can be more insidious than their OSS counterparts. In my professional experience, consumers are rarely educated enough to make tangible distinctions between technologically intricate products in terms of quality and performance. Often times marketing and deep pockets help fill this void, and the oft-quoted rule of thumb "if you can't dazzle them with brilliance, baffle them with bullshit" holds strong. Intel's "MHz rules" marketing of the past decade, which openly lead consumers to believe that the clock rate of a CPU was the deciding factor in performance (this is false) is a prime example of this phenomenon.
Because OSS generally lacks marketing and advertising, there is little room for consumer manipulation.
Moving on, the article completely misses the point when it quotes Sourceforge.net activity numbers:
Let's get one thing straight: almost all products meet an obscure end. There is a reason people don't use cassette decks, LPs, and eight-track formats anymore. People do not continue to drive cars engineered in the 1970s except in countries with restricted markets. I know of no one who currently uses an 18.8k modem to connect to the Internet. People rarely use floppy disks. There are reasons people don't use Windows 3.1 or the original Netscape Navigator. Tube amplifiers were displaced by solid state amplifiers which are currently being displaced by new, efficient digital amplifier designs.
Wristwatches are going the way of the dodo. Why carry a wristwatch if your mobile phone does it for you, in addition to any number of other useful features?
If the pattern isn't obvious, allow me to be blunt: even Rome had her day. It is the natural order of products and ideas to be useful in their inception and fade into obscurity after being displaced by new paradigms. The reason for the lack of activity on SourceForge.net is two fold:
The criticisms of the Economist article continue:
This is, again, backwards.
First of all, OSS projects don't "deploy" manpower. People who contribute find a project they're interested in, and they work on it. Often times companies invest in open source software, because it represents a cheaper, better product that they can leverage to cut costs and/or improve their primary products. In any event, the companies and individuals select the projects they want to work on, and not vice-versa.
Second, products that satisfy a consumer/user want--not the existence of expertise--drive the adoption rate of a given technology. Linux was not widely adopted because Linus Torvald has expertise in operating system design. Linux was adopted because it satisfied a real world need. It should also be noted that Linus was inspired by Minix (a kernel and operating system developed by Andrew Tanenbaum) to develop a capable UNIX-like operating system that could be run on a PC. In effect, a real-world user need was the first mover and not the influx of technically savvy professionals.
One issue with classical capitalistic models is that user wants are not as easily expressed. Research, development, and marketing departments spend vast resources trying to determine what it is consumers actually want, which sounds like a simple proposition in theory, but in practice is anything but. OSS skips this step--the consumer is often the user who is often the engineer. Eric Von Hippel has elaborated on this phenomenon substantially, especially in his writings concerning Lead Users.
Finally, the article makes the claim that OSS projects may be unable to maintain their momentum:
This is, again, completely backwards. Projects have a momentum that is not driven by people contributing so much as it is driven by people who have a need for the project. A bunch of OSS geeks do not congregate every Sunday to discuss what software they'll jointly produce or what innovation they should attempt in order to penetrate some untapped, currently undefined niche market. User wants drive this innovation, not a traditional capitalistic notion of product momentum.
Finally, there is little benefit to maintaining the momentum of an unpopular OSS project, just as there is little benefit to maintaining the momentum of an unpopular commercial project.
To summarize the article: the open-source model will continue to be applied in domains outside of software engineering and is a lucrative business model--albeit one with some outstanding issues. I agree with the former statement, but the latter is poorly reasoned and supported.
Example:
...However, it is unclear how innovative and sustainable open source can ultimately be. The open-source method has vulnerabilities that must be overcome if it is to live up to its promise. For example, it lacks ways of ensuring quality...
With regards to ensuring quality, the underlying assumption is that closed source, for-profit software development does have means of ensuring quality, which should set off a three-alarm fire in the collective brains of software developers everywhere. Closed source products that do not maintain quality are eliminated via natural selection (or some similar process), just as they are in the OSS model. It's pretty simple: release buggy commercial software, and users will start looking for other alternatives. Release buggy OSS, and users will start looking for other alternatives. Same concept applies.
I would add that capitalistic models can be more insidious than their OSS counterparts. In my professional experience, consumers are rarely educated enough to make tangible distinctions between technologically intricate products in terms of quality and performance. Often times marketing and deep pockets help fill this void, and the oft-quoted rule of thumb "if you can't dazzle them with brilliance, baffle them with bullshit" holds strong. Intel's "MHz rules" marketing of the past decade, which openly lead consumers to believe that the clock rate of a CPU was the deciding factor in performance (this is false) is a prime example of this phenomenon.
Because OSS generally lacks marketing and advertising, there is little room for consumer manipulation.
Moving on, the article completely misses the point when it quotes Sourceforge.net activity numbers:
Projects that fail to cope with open source's vulnerabilities usually fall by the wayside. Indeed, almost all of them meet this end. Of the roughly 130,000 open-source projects on SourceForge.net, an online hub for open-source software projects, only a few hundred are active, and fewer still will ever lead to a useful product. The most important thing holding back the open-source model, apparently, is itself.
Let's get one thing straight: almost all products meet an obscure end. There is a reason people don't use cassette decks, LPs, and eight-track formats anymore. People do not continue to drive cars engineered in the 1970s except in countries with restricted markets. I know of no one who currently uses an 18.8k modem to connect to the Internet. People rarely use floppy disks. There are reasons people don't use Windows 3.1 or the original Netscape Navigator. Tube amplifiers were displaced by solid state amplifiers which are currently being displaced by new, efficient digital amplifier designs.
Wristwatches are going the way of the dodo. Why carry a wristwatch if your mobile phone does it for you, in addition to any number of other useful features?
If the pattern isn't obvious, allow me to be blunt: even Rome had her day. It is the natural order of products and ideas to be useful in their inception and fade into obscurity after being displaced by new paradigms. The reason for the lack of activity on SourceForge.net is two fold:
- Sometimes, a product is simply finished. There isn't a reason to continue development on it anymore. The source code remains for people to use it as is, or incorporate it into new projects.
- As was mentioned above, Darwinian selection always applies. The "fittest" march ahead. Just like the vast majority of all species that have ever roamed the earth are extinct, so are many projects on SourceForge.net, for reasons that have little to do with the OSS model and everything to do with being fit.
The criticisms of the Economist article continue:
What is still missing are ways to “identify and deploy not just manpower, but expertise,” says Beth Noveck of New York University Law School (who is applying open-source practices to scrutinising software-patent applications, with an eye to invalidating dubious ones). In other words, even though open-source is egalitarian at the contributor level it can nevertheless be elitist when it comes to accepting contributions.
This is, again, backwards.
First of all, OSS projects don't "deploy" manpower. People who contribute find a project they're interested in, and they work on it. Often times companies invest in open source software, because it represents a cheaper, better product that they can leverage to cut costs and/or improve their primary products. In any event, the companies and individuals select the projects they want to work on, and not vice-versa.
Second, products that satisfy a consumer/user want--not the existence of expertise--drive the adoption rate of a given technology. Linux was not widely adopted because Linus Torvald has expertise in operating system design. Linux was adopted because it satisfied a real world need. It should also be noted that Linus was inspired by Minix (a kernel and operating system developed by Andrew Tanenbaum) to develop a capable UNIX-like operating system that could be run on a PC. In effect, a real-world user need was the first mover and not the influx of technically savvy professionals.
One issue with classical capitalistic models is that user wants are not as easily expressed. Research, development, and marketing departments spend vast resources trying to determine what it is consumers actually want, which sounds like a simple proposition in theory, but in practice is anything but. OSS skips this step--the consumer is often the user who is often the engineer. Eric Von Hippel has elaborated on this phenomenon substantially, especially in his writings concerning Lead Users.
Finally, the article makes the claim that OSS projects may be unable to maintain their momentum:
Once the early successes are established, it is not clear that the projects can maintain their momentum, says Christian Alhert, the director of Openbusiness.cc, which examines the feasibility of applying open-source practices to commercial ventures.
This is, again, completely backwards. Projects have a momentum that is not driven by people contributing so much as it is driven by people who have a need for the project. A bunch of OSS geeks do not congregate every Sunday to discuss what software they'll jointly produce or what innovation they should attempt in order to penetrate some untapped, currently undefined niche market. User wants drive this innovation, not a traditional capitalistic notion of product momentum.
Finally, there is little benefit to maintaining the momentum of an unpopular OSS project, just as there is little benefit to maintaining the momentum of an unpopular commercial project.
Multithreaded Mayham, Cont.
Two posts ago, I elaborated on a bug we found in the .NET 2.0 CLR when attempting to spawn multiple threads at a lower priority than the spawning thread. However, I realized this morning that I didn't talk about what we did to actually address the bug in our code.
Short answer: we did the best we could, but really the only full-proof "fix" is for MSFT to release a patch or wait for the next version of .NET. Our fix amounted to protecting all of our BeginInvoke calls with a lock to prevent two of them from being called at the same time, which did fix the bug.
However, one issue with this fix is it still wouldn't address the same bug in third party code that we execute. There isn't much to be done about that. Because we rely on the CLR to function properly, and other code may use the offending code in the CLR, we're somewhat at the mercy of MSFT on this one, which is always scary, since they're an 800 lb. gorilla and we're something more similar to toe fungus.
Short answer: we did the best we could, but really the only full-proof "fix" is for MSFT to release a patch or wait for the next version of .NET. Our fix amounted to protecting all of our BeginInvoke calls with a lock to prevent two of them from being called at the same time, which did fix the bug.
However, one issue with this fix is it still wouldn't address the same bug in third party code that we execute. There isn't much to be done about that. Because we rely on the CLR to function properly, and other code may use the offending code in the CLR, we're somewhat at the mercy of MSFT on this one, which is always scary, since they're an 800 lb. gorilla and we're something more similar to toe fungus.
Friday, October 06, 2006
The Not-So-Old New Thing
Raymond Chen is one of the proverbial oldboys at MSFT. He runs this blog.
...he is apparantly famous enough to have his own wikipedia entry as well (http://en.wikipedia.org/wiki/Raymond_Chen), although then again the requirements for having your own wikipedia page aren't exactly breathtaking.
Okay, okay, not trying to be a curmudgeon, but I digress: Raymond is generally considered to be a very knowledgeable, somewhat prolific entity in the Win32 programming world. That being said, I think he made a very basic error in one of his recent blog posts:
http://blogs.msdn.com/oldnewthing/archive/2006/06/01/612970.aspx
The posting itself makes a very good point about the dangers of the CS_OWNDC class style. However, the following function is a poor example of quality code:
void FunnyDraw(HWND hwnd, HFONT hf1, HFONT hf2)
{
HDC hdc1 = GetDC(hwnd);
HFONT hfPrev1 = SelectFont(hdc1, hf1);
UINT taPrev1 = SetTextAlign(hdc1, TA_UPDATECP);
MoveToEx(hdc1, 0, 0, NULL);
HDC hdc2 = GetDC(hwnd);
HFONT hfPrev2 = SelectFont(hdc2, hf2);
for (LPTSTR psz = TEXT("Hello"); *psz; psz++)
{
POINT pt;
GetCurrentPositionEx(hdc1, &pt);
TextOut(hdc2, pt.x, pt.y + 30, psz, 1);
TextOut(hdc1, 0, 0, psz, 1);
}
SelectFont(hdc1, hfPrev1);
SelectFont(hdc2, hfPrev2);
SetTextAlign(hdc1, taPrev1);
ReleaseDC(hwnd, hdc1);
ReleaseDC(hwnd, hdc2);
}
...the manual, unprotected calls to GetDC and ReleaseDC are crude and error prone. When an application makes a call to GetDC (which generally shouldn't be done--most people using GetDC don't actually need to), it must be followed with a call to ReleaseDC. This is a pretty basic programming principle: if some object or resource is allocated by your program, you need to give it back at some future time.
My beef is with the manual calls to GetDC/ReleaseDC. If the above code used the CClientDC class, it would automatically call ReleaseDC when the declared CClientDC object went out of scope, thus removing the responsibility from the programmer.
Writing good, maintainable code is about more than making your code error-free; it's about bullet-proofing your code for future programmers who may not know better. So, your successor lumbers along, and decides to throw in a return statement midway through this call, alienating the HDC object--had Raymond originally used CClientDC, this wouldn't have been a problem.
Likewise, if the code throws an exception, the class automatically goes out of scope. Problem solved. Given that there is no error checking on the inputs (unforgiveable sin #2, but I'll leave that rant for another day), the possibility of an exception being thrown (and then caught somewhere up in the call stack) is pretty good.
When I presented this minor edit to Raymond, he had some terse, evasive comments to the effect of: "I think you missed the point of the article. CClientDC wouldn't have helped any." Well, duh. Of course it wouldn't have helped any--but that's not the point I'm making! The bigger observations here are: most of the time, using GetDC isn't appropriate--the very use of GetDC itself is suspect. Second, using objects that always have a requisite "cleanup" action without having that cleanup managed by the C notion of scope is code that isn't worth fresh cow dung.
When I clarified myself, I get yet another strangely evasive comment: "I already explained multiple times why my samples do not use any class libraries. Plain C is the common language. If you want to use a particular dialect then more power to you." Okay, fine: so write your own basic wrapper class (or merely copy the code for CClientCD, which is freely available), but for God's sake, stop proliferating crap programming practices on people who should know better!
MSFT has this strange habit of doing the above; it all reminds me of the DirectShow filter pointers fiasco. DirectShow filters are COM objects, and the vast, vast majority of all of the samples provided by MSFT use raw COM pointers. Needless to say, this is moronic: and because of it, the vast majority of DirectShow programs are, to use the parlance of our times, Seriously Fucked. The problem is programmers forgetting to call Release() on their COM objects, or having the program encounter an error/throw an exception, and not clean up after itself because a programmer didn't have appropriate error checking in one of several hundred places they'd need to put it. Most people end up using raw pointers because all of the sample code provided to them uses raw pointers. In other words, it's a "do as I say, not as I do" sort of situation--nobody well versed in the ways of COM would touch a raw COM ptr, but in this asinine push to "not use a particular dialect," they are actually just proliferating garbage code.
The solution to DShow woes is to use CComPtr. CComPtr protects you from this, because when a declared CComPtr object goes out of scope, it automagically calls Release() on the underlying COM object. The programmer no longer has to be concerned with it. To not use this sort of automatic, basic protection while programming is irresponsible at best, and demented at worst.
...he is apparantly famous enough to have his own wikipedia entry as well (http://en.wikipedia.org/wiki/Raymond_Chen), although then again the requirements for having your own wikipedia page aren't exactly breathtaking.
Okay, okay, not trying to be a curmudgeon, but I digress: Raymond is generally considered to be a very knowledgeable, somewhat prolific entity in the Win32 programming world. That being said, I think he made a very basic error in one of his recent blog posts:
http://blogs.msdn.com/oldnewthing/archive/2006/06/01/612970.aspx
The posting itself makes a very good point about the dangers of the CS_OWNDC class style. However, the following function is a poor example of quality code:
void FunnyDraw(HWND hwnd, HFONT hf1, HFONT hf2)
{
HDC hdc1 = GetDC(hwnd);
HFONT hfPrev1 = SelectFont(hdc1, hf1);
UINT taPrev1 = SetTextAlign(hdc1, TA_UPDATECP);
MoveToEx(hdc1, 0, 0, NULL);
HDC hdc2 = GetDC(hwnd);
HFONT hfPrev2 = SelectFont(hdc2, hf2);
for (LPTSTR psz = TEXT("Hello"); *psz; psz++)
{
POINT pt;
GetCurrentPositionEx(hdc1, &pt);
TextOut(hdc2, pt.x, pt.y + 30, psz, 1);
TextOut(hdc1, 0, 0, psz, 1);
}
SelectFont(hdc1, hfPrev1);
SelectFont(hdc2, hfPrev2);
SetTextAlign(hdc1, taPrev1);
ReleaseDC(hwnd, hdc1);
ReleaseDC(hwnd, hdc2);
}
...the manual, unprotected calls to GetDC and ReleaseDC are crude and error prone. When an application makes a call to GetDC (which generally shouldn't be done--most people using GetDC don't actually need to), it must be followed with a call to ReleaseDC. This is a pretty basic programming principle: if some object or resource is allocated by your program, you need to give it back at some future time.
My beef is with the manual calls to GetDC/ReleaseDC. If the above code used the CClientDC class, it would automatically call ReleaseDC when the declared CClientDC object went out of scope, thus removing the responsibility from the programmer.
Writing good, maintainable code is about more than making your code error-free; it's about bullet-proofing your code for future programmers who may not know better. So, your successor lumbers along, and decides to throw in a return statement midway through this call, alienating the HDC object--had Raymond originally used CClientDC, this wouldn't have been a problem.
Likewise, if the code throws an exception, the class automatically goes out of scope. Problem solved. Given that there is no error checking on the inputs (unforgiveable sin #2, but I'll leave that rant for another day), the possibility of an exception being thrown (and then caught somewhere up in the call stack) is pretty good.
When I presented this minor edit to Raymond, he had some terse, evasive comments to the effect of: "I think you missed the point of the article. CClientDC wouldn't have helped any." Well, duh. Of course it wouldn't have helped any--but that's not the point I'm making! The bigger observations here are: most of the time, using GetDC isn't appropriate--the very use of GetDC itself is suspect. Second, using objects that always have a requisite "cleanup" action without having that cleanup managed by the C notion of scope is code that isn't worth fresh cow dung.
When I clarified myself, I get yet another strangely evasive comment: "I already explained multiple times why my samples do not use any class libraries. Plain C is the common language. If you want to use a particular dialect then more power to you." Okay, fine: so write your own basic wrapper class (or merely copy the code for CClientCD, which is freely available), but for God's sake, stop proliferating crap programming practices on people who should know better!
MSFT has this strange habit of doing the above; it all reminds me of the DirectShow filter pointers fiasco. DirectShow filters are COM objects, and the vast, vast majority of all of the samples provided by MSFT use raw COM pointers. Needless to say, this is moronic: and because of it, the vast majority of DirectShow programs are, to use the parlance of our times, Seriously Fucked. The problem is programmers forgetting to call Release() on their COM objects, or having the program encounter an error/throw an exception, and not clean up after itself because a programmer didn't have appropriate error checking in one of several hundred places they'd need to put it. Most people end up using raw pointers because all of the sample code provided to them uses raw pointers. In other words, it's a "do as I say, not as I do" sort of situation--nobody well versed in the ways of COM would touch a raw COM ptr, but in this asinine push to "not use a particular dialect," they are actually just proliferating garbage code.
The solution to DShow woes is to use CComPtr. CComPtr protects you from this, because when a declared CComPtr object goes out of scope, it automagically calls Release() on the underlying COM object. The programmer no longer has to be concerned with it. To not use this sort of automatic, basic protection while programming is irresponsible at best, and demented at worst.
Thursday, October 05, 2006
Welcome...And .NET Multithreading Woes
Welcome!
Yes, this is my first blog posting. I decided to start blogging both out of a sense of bordom, as well as a desire to expound upon a few topics for my own personal entertainment. Anyways, I don't need to tire anyone with more details than that, so....on to the first post.
Multithreading can be nasty business. Actually, to be totally precise, multithreading can be ugly, vicious, maloderous, heinously evil business. Learning to write multithreaded code (and write it well) can take years of practice and experimentation, and requires an intimate knowledge of how the operating system schedules threads.
A month or two ago, a coworker of mine narrowed in on a strange hang in our application where a BeginInvoke .NET call would take an extraordinary amount of time and consume 100% of available CPU. The issue was only visible on single-processor machines, and when attempting to start threads at a lower priority.
After investigating the issue, we stumbled across this forum post, which outlined what our problem was quite clearly. In .NET 1.1, when starting a new thread, the .NET runtime did not attempt to wait for the thread to start before returning. It's worth noting that most threading routines work like this; a call is made to kick off a new thread, but when the call returns, the new thread may or may not be up and running, since the whole thing obviously needs to be asynchronous. A common means of "waiting" for the thread to start is to use a WaitForSingleObject call, or some other similar eventing derivative.
Well, someone clearly thought this behavior to be undesireable. In .NET 2.0, someone added the following code to the CLR to make sure the newly spawned thread was running before returning to the calling application:
More or less, the above code attempts to "switch" (in quotes to indicate this is actually bogus) to the new thread while the new thread has not failed to begin, and the state is still unstarted. This implementation had a serious flaw when dealing with threads of a lower priority, in addition to several other major blemishes.
To really get an idea of the severity of this bug, let's take a look at the documentation for __SwitchToThread():
...so, to recap, the person writing the above code though to themselves "gee, I'll just switch over to that thread I just kicked off. Y'know, hand over the CPU...", except it doesn't work like that: what they really did was tell the scheduler in the OS to stop giving the current thread CPU time, and give some other thread CPU time. The rub here is the "other" thread may or may not be the thread we just started. If the thread we just started is a low priority thread, it is very likely that there is some other normal priority thread that needs CPU time.
Now, imagine running multiple instances of the above code, both of which are running at normal priority, but trying to launch threads of lower priority. Parent Thread A calls __SwitchToThread(), which tells the OS to execute the next waiting thread. The OS sees that there's another thread that needs CPU time, and promptly schedules Parent Thread B, which promptly calls __SwitchToThread, and goes back to Parent Thread A! The net result is that the code will ping-pong between parent threads waiting for their respective child threads to begin, all while consuming 100% of the CPU and incurring a huge amount of context switching. In the instance of two or more parent threads waiting for child threads, this quickly loads the system and locks out the child threads from receiving any CPU time.
All of this thrashing will continue until something called the "balance set manager" comes in and coughs up some cycles for the starving threads. Everyone loves a thrashing OS early in the morning. I prefer mine with crumpets and tea.
The first error here is that polling is bad, m'kay?! The code above basically amounts to the proverbial "...are we there yet? are we there yet? are we there yet?...(x200,000,000 iterations)...are we there yet?" without ever actually doing any real work. In this instance, the polling has the added side effect of causing the very thing being waited upon to never begin!
A terrible, awful, evil "fix" for this code could be:
...Sleep will make the thread relinquish its CPU time back to the OS, which would allow the pathetic underling threads to get a piece of the action. However, this is still polling! A better solution to the problem would be to have the code do a WaitForSingleObject/WaitForMultipleObject, and have the spawned thread signal when it's up and running.
Error number two is not understanding how the scheduler works, and totally misunderstanding how __SwitchToThread() functions. The author clearly didn't understand how the scheduler works in the OS, which is absolutely key if multithreaded code is on the table. They may have tested their code too, but another facet of this issue is that dual-core/dual-CPU machines will not reproduce the issue, because a second core can service the newly spawned threads. The move towards multithreaded code thus has seriously implications for not only multi-processor computers, but for single processor machines as well. A developer writing code now needs to be sure to test against a single CPU machine if their primary machine is multi-core.
Yes, this is my first blog posting. I decided to start blogging both out of a sense of bordom, as well as a desire to expound upon a few topics for my own personal entertainment. Anyways, I don't need to tire anyone with more details than that, so....on to the first post.
Multithreading can be nasty business. Actually, to be totally precise, multithreading can be ugly, vicious, maloderous, heinously evil business. Learning to write multithreaded code (and write it well) can take years of practice and experimentation, and requires an intimate knowledge of how the operating system schedules threads.
A month or two ago, a coworker of mine narrowed in on a strange hang in our application where a BeginInvoke .NET call would take an extraordinary amount of time and consume 100% of available CPU. The issue was only visible on single-processor machines, and when attempting to start threads at a lower priority.
After investigating the issue, we stumbled across this forum post, which outlined what our problem was quite clearly. In .NET 1.1, when starting a new thread, the .NET runtime did not attempt to wait for the thread to start before returning. It's worth noting that most threading routines work like this; a call is made to kick off a new thread, but when the call returns, the new thread may or may not be up and running, since the whole thing obviously needs to be asynchronous. A common means of "waiting" for the thread to start is to use a WaitForSingleObject call, or some other similar eventing derivative.
Well, someone clearly thought this behavior to be undesireable. In .NET 2.0, someone added the following code to the CLR to make sure the newly spawned thread was running before returning to the calling application:
while (!pNewThread->HasThreadState(Thread::TS_FailStarted) &&
pNewThread->HasThreadState(Thread::TS_Unstarted))
{
__SwitchToThread(0);
}
More or less, the above code attempts to "switch" (in quotes to indicate this is actually bogus) to the new thread while the new thread has not failed to begin, and the state is still unstarted. This implementation had a serious flaw when dealing with threads of a lower priority, in addition to several other major blemishes.
To really get an idea of the severity of this bug, let's take a look at the documentation for __SwitchToThread():
Causes the calling thread to yield execution to another thread that is ready to run on the current processor. The operating system selects the next thread to be executed.
...so, to recap, the person writing the above code though to themselves "gee, I'll just switch over to that thread I just kicked off. Y'know, hand over the CPU...", except it doesn't work like that: what they really did was tell the scheduler in the OS to stop giving the current thread CPU time, and give some other thread CPU time. The rub here is the "other" thread may or may not be the thread we just started. If the thread we just started is a low priority thread, it is very likely that there is some other normal priority thread that needs CPU time.
Now, imagine running multiple instances of the above code, both of which are running at normal priority, but trying to launch threads of lower priority. Parent Thread A calls __SwitchToThread(), which tells the OS to execute the next waiting thread. The OS sees that there's another thread that needs CPU time, and promptly schedules Parent Thread B, which promptly calls __SwitchToThread, and goes back to Parent Thread A! The net result is that the code will ping-pong between parent threads waiting for their respective child threads to begin, all while consuming 100% of the CPU and incurring a huge amount of context switching. In the instance of two or more parent threads waiting for child threads, this quickly loads the system and locks out the child threads from receiving any CPU time.
All of this thrashing will continue until something called the "balance set manager" comes in and coughs up some cycles for the starving threads. Everyone loves a thrashing OS early in the morning. I prefer mine with crumpets and tea.
The first error here is that polling is bad, m'kay?! The code above basically amounts to the proverbial "...are we there yet? are we there yet? are we there yet?...(x200,000,000 iterations)...are we there yet?" without ever actually doing any real work. In this instance, the polling has the added side effect of causing the very thing being waited upon to never begin!
A terrible, awful, evil "fix" for this code could be:
while (!pNewThread->HasThreadState(Thread::TS_FailStarted) &&pNewThread->HasThreadState(Thread::TS_Unstarted))
{
__SwitchToThread(0);
Sleep(1);
}...Sleep will make the thread relinquish its CPU time back to the OS, which would allow the pathetic underling threads to get a piece of the action. However, this is still polling! A better solution to the problem would be to have the code do a WaitForSingleObject/WaitForMultipleObject, and have the spawned thread signal when it's up and running.
Error number two is not understanding how the scheduler works, and totally misunderstanding how __SwitchToThread() functions. The author clearly didn't understand how the scheduler works in the OS, which is absolutely key if multithreaded code is on the table. They may have tested their code too, but another facet of this issue is that dual-core/dual-CPU machines will not reproduce the issue, because a second core can service the newly spawned threads. The move towards multithreaded code thus has seriously implications for not only multi-processor computers, but for single processor machines as well. A developer writing code now needs to be sure to test against a single CPU machine if their primary machine is multi-core.
Subscribe to:
Posts (Atom)
